
I wrote that GLP-1 drugs might fight cancer. Then I looked at the one-click research tool that produced the study, and the thousand more like it that land in the journals every year.
A few weeks ago I wrote up a study suggesting the drug in my own refrigerator might slow the spread of cancer. I take tirzepatide, so a headline like that lands differently for me than most drug news. I read the actual paper instead of the press release, flagged that it was observational, and said I was not changing anything. I stand by that post. What I did not say, because I did not yet understand it, is that the study came out of a tool that is quietly flooding medical journals with results exactly like it. Some of those results are careful. A lot of them are junk. And from the outside they look identical.
The tool is called TriNetX, and a recent investigation in Science is what sent me back to my own work with a more skeptical eye. I want to be fair to it. TriNetX is a genuinely useful research tool, and a trained epidemiologist can do real work with it. The problem is how easily it lets someone untrained skip the hard part.
A research platform that turns one click into a published paper
TriNetX started in 2013 as a way to help drug companies find patients for clinical trials. It has since grown into the largest network of its kind, holding the de-identified electronic health records of more than 300 million patients across over 30 countries. Hospitals and medical schools feed in their records and get to use the platform for free. Drug companies and research firms pay for access.
A researcher at a member hospital logs in, builds two groups of patients by typing in billing codes, say everyone on a GLP-1 drug versus everyone on a different diabetes drug, and picks an outcome like cancer or death. Then they click one button. The platform pairs the two groups so they look alike on the things written in their charts, draws a survival curve, and reports a hazard ratio, which is just the rate of bad outcomes in one group measured against the other, all laid out like a real study. You do not need statistics training to do it, or grant money, or even a hypothesis you believed before you started. People who study this call it push-button research, and the description is fair. You can go from idea to publishable-looking chart in an afternoon.
That ease is the whole problem. The same features that make TriNetX useful for a trained epidemiologist make it a machine for generating impressive nonsense in the hands of someone who has never been taught how observational data lies to you. Most of these papers, Science found, come out of U.S. medical schools, usually with a medical student or resident as the lead author, the people who now lean on a long publication list to stand out when they apply for competitive residencies.
I am not a stranger to that pressure. I spent my career in machine learning, and years before that in grad school, inside the same publish-or-perish world these trainees live in. You learn early how to stare at a pile of data hunting for a real finding that will hold up to scrutiny. But a tool that does it in an afternoon, with no code and a finished chart at the end, takes that to a level I never saw in my own field.
Get the next one in your inbox
I write about longevity, training, and preventive health weekly — without the guru worship. Free, no spam, unsubscribe whenever.
What I found when I counted the papers myself
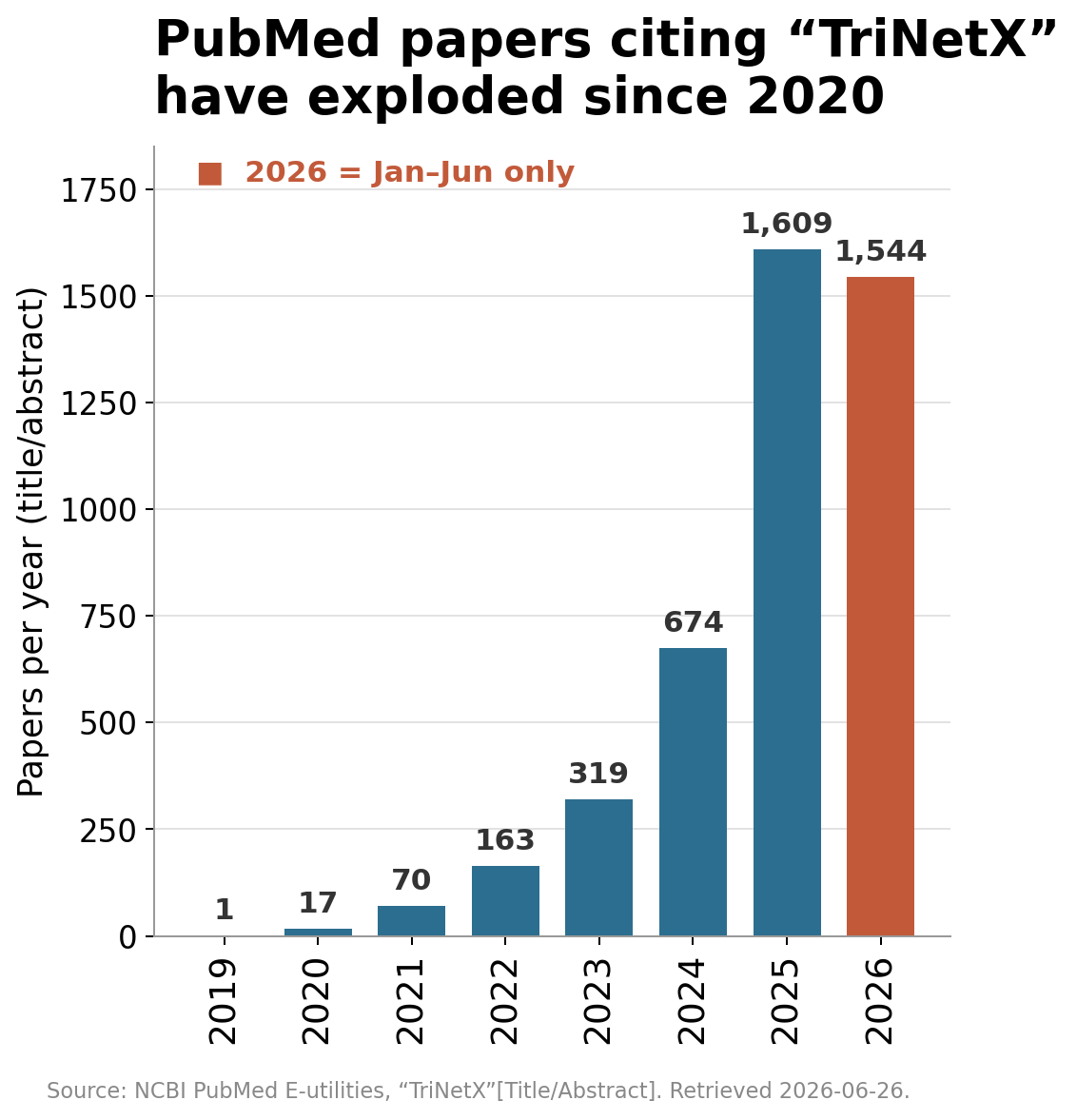
Science reported the publication numbers from a database called Dimensions. I do not like citing a count I cannot reproduce, so I ran my own using PubMed, which anyone can query for free. I searched for the term TriNetX in the title or abstract field and counted the results by publication year.1
In 2019 there was one. In 2022 there were 163. In 2025 there were 1,609, and the first half of 2026 alone already has more than 1,500. My PubMed numbers come in lower than the figures Science cited because Dimensions indexes more sources than PubMed does, but the shape is the same either way, and it is the shape that matters.
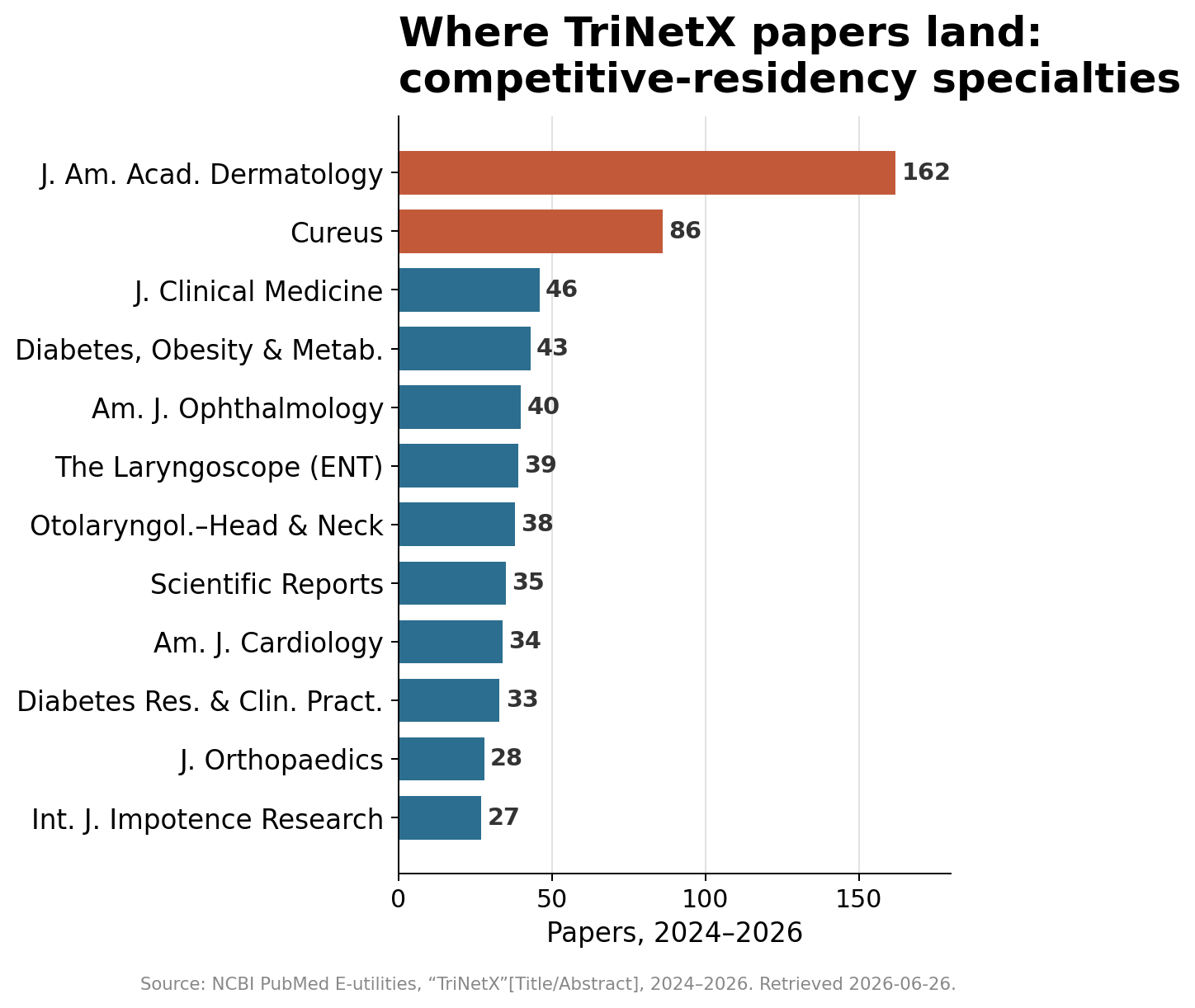
When I looked at where these papers land, the pattern told its own story. The single biggest home for them is a dermatology journal, followed by a high-volume journal that publishes almost anything, and then a run of ophthalmology, ear-nose-throat, orthopedic, and urology titles. Those are among the hardest residencies to match into. The journals are a map of where the career pressure is highest.
Immortal time, and the broken-leg problem
Two flaws show up over and over.
The first is immortal-time bias. Picture a study of people who had a heart attack, asking whether a certain drug helps them live longer. The drug group is defined as everyone who filled a prescription for it within a year of the heart attack. The catch is that to fill a prescription at month six, you have to still be alive at month six. Anyone who died in week two never had the chance, so they get sorted into the comparison group instead. The drug group is now secretly pre-selected for survivors. The drug looks life-saving when all the study really measured is that people who lived longer lived longer. This is not hypothetical. A 2026 study in the journal Angiology used TriNetX to report that a diabetes drug cut deaths after a heart attack from 7.6 percent to 3.1 percent, and it defined the treated group as people who started the drug within a year of the attack. That is the trap, built right into the design.
The second is collider bias, and the cleanest way to see it has nothing to do with drugs. Imagine that asthma and a broken leg are completely unrelated in the general population, which they are. Both, though, can land you in the hospital. If you study only hospitalized patients, broken legs will look protective against asthma, because among people already admitted, the ones there for a broken leg did not need asthma to explain why they came in. The link is an illusion manufactured by who you chose to look at. Now put the real variables in. Both starting a weight-loss drug and developing cancer make a person turn up in the health system more often, and you only exist in an electronic-records study if you turned up. Being in the database is the hospital door here, and the study has already walked everyone through it. Condition on that shared effect, and the drug can look protective against a cancer it never touched.
The cancer paper that shows how bad it gets
The clearest example in the Science piece is a 2024 study, published in a journal called Cancers, that used TriNetX records from more than a million patients with obesity. It claimed that GLP-1 drugs lowered the risk of a long list of cancers, gastrointestinal, breast, prostate, skin, and more, by thirty to fifty percent. The authors called it compelling evidence.
Other researchers called it something else. A formal critique published in the same journal the next year, funded by Cancer Research UK and declaring no industry ties, walked through seven separate ways the original analysis could manufacture a benefit that is not real. My favorite, because anyone can grasp it, is about timing. A cancer takes years, often decades, to grow from its first cells into something a scan or a biopsy can catch. A drug that appears to cut cancer rates within a few years of someone starting it is not preventing cancer that fast. It is far more likely detecting one of the biases above. A second flaw they raised is almost funny in its backwardness. GLP-1 drugs lower the risk of dying from heart disease, which means people who take them live longer, which gives them more time to be diagnosed with cancer, not less. A careless analysis can flip that into the drug looking protective.
I do not think this is really about one bad paper. It is what happens when a tool this easy meets a reward this large, and the careful work and the careless work end up in the journals together, where from the outside they can look a lot alike.
The newest wrinkle is the one I find hardest to shake. A 2026 paper in the European Journal of Epidemiology found published TriNetX studies that described doing a statistical correction the platform cannot actually perform. When the authors asked seven AI chatbots how to do that correction in TriNetX, six of them confidently described methods that do not exist. So at least some of these papers appear to have methods sections written by an AI that invented the procedure, and reviewers who waved it through. The work can now be wrong from the raw data all the way up to the description of how it was supposedly done.
The schools and journals share the blame
It would be easy to stop at the students, but that lets the institutions off too lightly. Medical schools hand trainees this tool precisely because it is a fast way to produce publications, and most attach no instruction on how it can mislead. One of the researchers raising the alarm, Joshua Wang, does the opposite. Before anyone at his hospital can touch TriNetX, they spend an hour with him while he shows how quickly it produces beautiful, meaningless results, the point being to leave them a little afraid of it. That hour is rare. The body that runs the U.S. residency application process has defended learning by doing, though it now says it will start rewarding the quality of an applicant’s research over the sheer count of it, which is the incentive finally bending the right way.
The journals deserve their share too. Every one of these papers cleared peer review, at titles ranging from established specialty journals to high-volume venues that publish almost anything. Reviewers are supposed to be the filter, and they keep passing work shot through with the biases above. TriNetX makes roughly this argument in its own defense, that the tool is sound in trained hands and that screening out bad studies is the job of peer review and not the platform, and on that narrow point the company is right. The filter built to catch this is the one that failed.
How I read the next “Ozempic also cures” headline
I am not throwing out my earlier post. The study it covered was, by the standards of this genre, one of the more careful ones. It compared GLP-1 users to people on a different diabetes drug rather than to people on nothing, it threw out anyone whose cancer progressed in the first three months, and it had a plausible biological thread in the tumor tissue. Those are exactly the guardrails the bad papers skip. But it was still observational, still built on this same platform, and still one entry in a flood of more than a thousand a year. I gave it the right amount of caution. I just did not realize how much of that flood was junk.
I read these stories a lot more skeptically now. When a drug suddenly seems to help with something it was never built for, I want to know what they compared it against, because comparing drug-takers to people on nothing stacks the deck before the study even starts. I want to know whether the design quietly rewards patients for surviving long enough to fill the prescription. And I want to know whether the benefit shows up faster than the disease could even form. A drug that looks protective against a dozen unrelated diseases at once usually is not. You are looking at the fingerprints of a method, not a medicine.
The drugs may turn out to lower the risk of some of these cancers. I hope they do, since I am on one. But hope is not evidence, and a clean-looking chart from a one-click tool is not either.
1. The exact query is TriNetX[Title/Abstract], and I pulled the numbers on June 26, 2026, so anyone can rerun it and check me. ↩
About Gunnar
Gunnar is 53. He lost about 170 pounds, trains in a garage gym, and writes DadStrengthDaily from personal experience, citing primary sources where he can. He also moderates r/ProactiveHealth. He is not a doctor, and nothing here is medical advice. Talk to your own doctor before acting on anything, especially GLP-1s, TRT, blood pressure, sleep apnea, and cancer screening.